The Problem
Writing LinkedIn posts that actually engage takes time: researching the topic, tailoring the tone, and crafting a hook. Most professionals skip posting entirely rather than start from scratch. This gives them a solid starting point they can refine in minutes.
Why AI
A single prompt produces generic content. By separating research (Perplexity), generation (OpenAI), and evaluation (LLM-as-judge), each stage does one thing well. Weak drafts get flagged and improved before reaching you.
How It Works
1
User inputs topic and selects target audience (engineers, founders, marketers)
2
Perplexity retrieves current data, trends, and citations to ground the content
3
OpenAI generates audience-tailored draft using research context
4
LLM-as-judge evaluates draft quality and flags weak hooks or unclear CTAs
5
User receives polished draft ready for final personalization
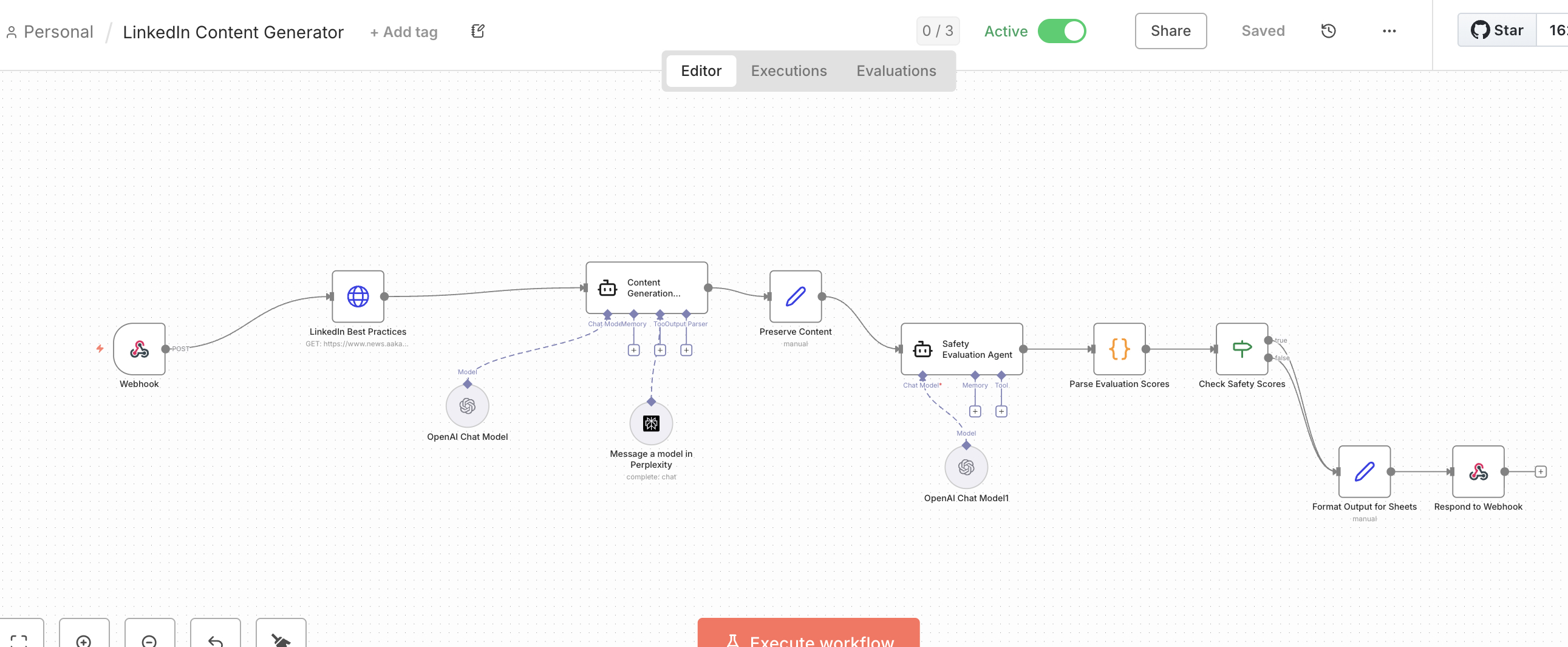
How We Built It
| Decision | Alternative | Product Rationale |
|---|---|---|
| Perplexity for retrieval | OpenAI web browsing | Grounded output with citations increases user trust |
| LLM-as-judge eval step | Single generate-and-done | Quality gate improves perceived reliability at scale |
| n8n orchestration | Custom Python script | Visual debugging accelerates iteration; model-agnostic design future-proofs architecture |
| Audience presets | Free-form input | Lower friction drives adoption; constraints improve output consistency |
What I Learned
- 💡 Adding an LLM evaluation step at the end catches quality issues automatically, without needing manual review.
- 💡 This workflow has three separate steps: research, writing, and evaluation. One model doing all three rushes through research to get to writing, and can't objectively evaluate its own work.