The Problem
Sales and product teams need fresh competitor intel, but gathering it manually is a time sink. By the time someone compiles a report, it's already stale. Most teams either skip it or assign it to a junior analyst who spends hours on what should take minutes.
Why AI
Rule-based automation fails because competitor content is unstructured: press releases, blog posts, and pricing pages all look different. An LLM can read, synthesize, and extract meaning from messy web content that would break traditional scrapers.
How It Works
1
Pull competitor names from a shared Google Sheet
2
Research each company via Brave Search (what they do, products, positioning, recent news)
3
Pass raw findings through a two-stage LLM chain:
Stage 1: Research agent synthesizes raw search data into structured summaries
Stage 2: Strategic analyst extracts patterns, threats, opportunities, and recommended actions
4
Convert markdown output to styled HTML
5
Email formatted report to stakeholders automatically
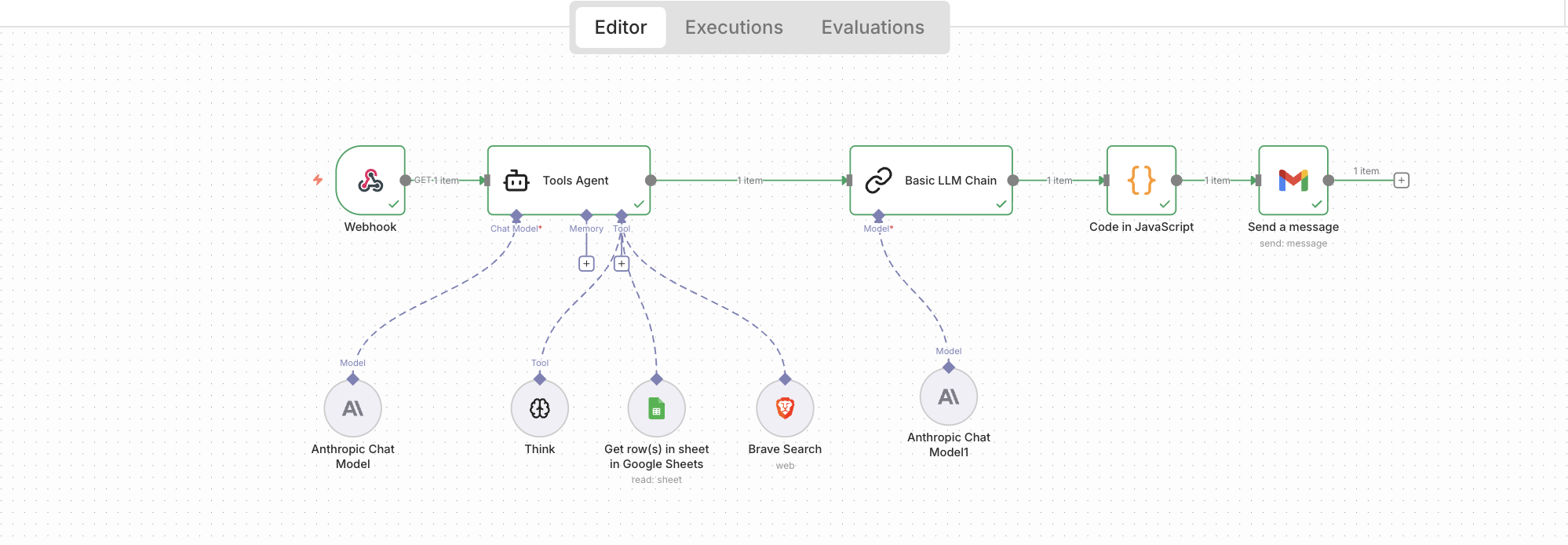
How We Built It
| Decision | Alternative | Why I Chose This |
|---|---|---|
| Google Sheets input | Custom form / UI | Non-technical teammates can update the competitor list without asking me |
| n8n workflow | Custom Python | Visual debugging and fast iteration; easier to maintain and demo |
| Two-stage LLM chain | Single mega-prompt | Separates research from analysis, producing sharper and more reliable output |
| Think tool for planning | Direct execution | Agent plans its approach before acting, reducing errors on multi-step tasks |
| Tuned tool descriptions | Generic descriptions | Guides agent behavior on when to search, read from Sheets, or reason |
| Email output | Dashboard | Meets stakeholders where they are; no new tool to adopt or login required |
| Claude Sonnet 4 | GPT-4 / Haiku | Best balance of cost, speed, and reasoning quality for multi-step tasks |
| Actionable insights | Raw data dumps | Focus on threats, opportunities, and recommended actions stakeholders can act on |
What I Learned
- 💡 Even a powerful model guesses when prompts are vague. A clear prompt on a smaller model often works better because it follows directions instead of inferring what you want.
- 💡 The order in which the agent calls tools comes from two places: the agent prompt and each tool's description. Both need to be specific for routing to work.
- 💡 In this case, a two-stage LLM chain was important because research needs to be complete before analysis begins. One LLM doing both tends to skip gathering facts and jump to conclusions.