The Problem
Not everyone has time to read. Busy professionals want to learn while commuting, exercising, or doing chores. But finding quality audio content on niche topics is hit-or-miss, and producing it yourself takes hours.
Why AI
This combines three AI capabilities that didn't exist together before: real-time research (Perplexity), synthesis (LLM), and natural speech (TTS). The quality gate ensures only helpful content gets converted, saving TTS costs on weak outputs.
How It Works
1
User submits topic query
2
AI Agent invokes Perplexity tool to retrieve current, cited information
3
Agent synthesizes research into audio-optimized script
4
LLM-as-judge evaluates helpfulness before proceeding
5
TTS converts approved scripts to natural speech
6
User receives quality-gated audio brief
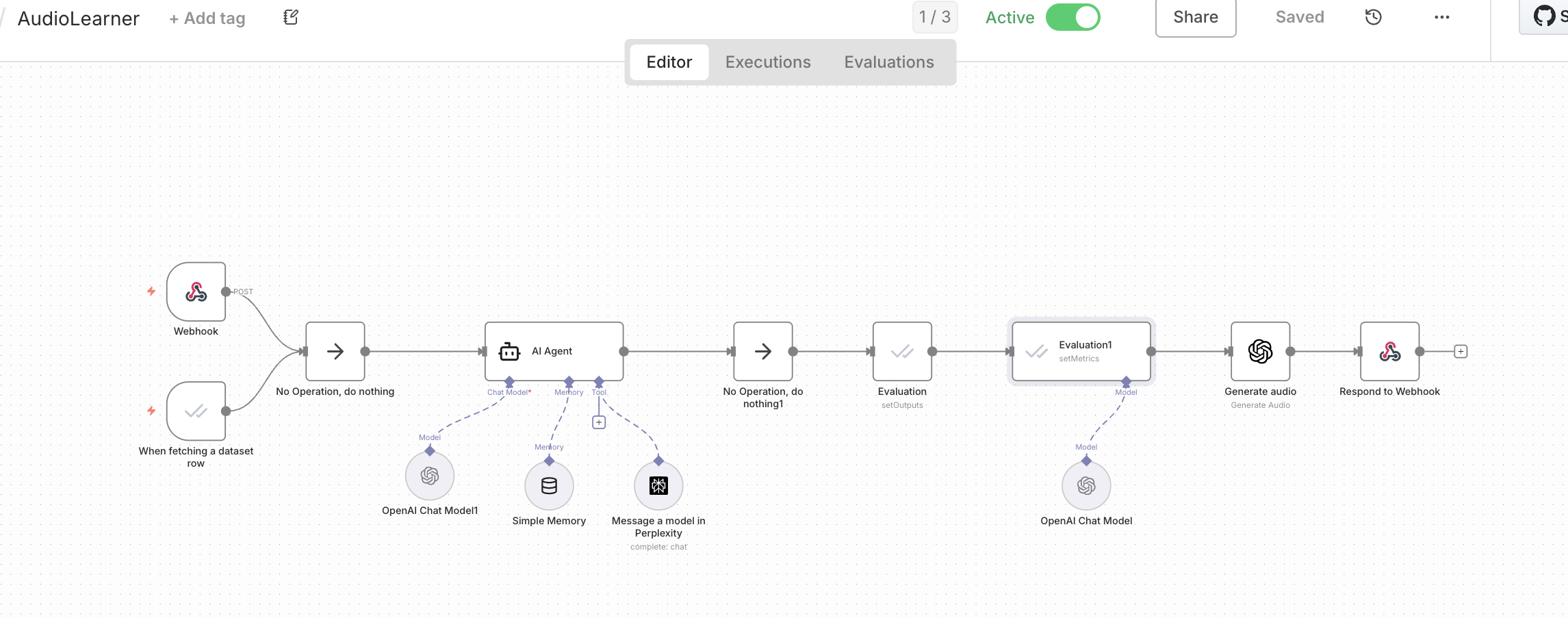
How We Built It
| Stage | Technology | Product Rationale |
|---|---|---|
| Agent | OpenAI + Simple Memory | Agentic architecture enables dynamic tool use; memory supports follow-up queries |
| Research Tool | Perplexity | Grounded retrieval with citations prevents hallucinated facts in audio |
| Evaluation | n8n Eval (Helpfulness) | Quality gate prevents low-value outputs from consuming TTS credits |
| Narration | OpenAI TTS | Natural voice quality critical for audio content users will actually finish |
| Audio Length | 2-3 minute cap | Allows more users and testers to try the feature without hitting API limits |
Why evaluate before TTS: Audio generation is the most expensive step. An LLM-as-judge quality gate ensures only helpful summaries proceed, optimizing both cost and user experience.
What I Learned
- 💡 To ensure content is helpful, I used n8n's evaluation node which uses an LLM-as-judge to score the output. Based on the score, the workflow decides whether to regenerate or return the result.
- 💡 AI-generated content without real data sounds generic. Grounding the output in researched facts made the difference between content users skip and content they finish.